
Loendusmeeskond jätkab tööd
Millega tegelevad rahvaloendajad 2012. aasta suvel? Kuidas loendatakse loendamata jäänud inimesi? Rahvaloenduse esmaste tulemuste avaldamisest on juba mitu kuud möödas, millega tegeletakse edasi? Loendusmeeskonna põhitegevus on käesoleval ajal loendusandmete korrastamine, samuti nendest avaldatavate tunnuste moodustamine. Näiteks tuleb kõik sünni- ja varasemad elukohad teisendada praegu kehtiva haldusjaotuse tasemele, loendatud inimesed rühmitada leibkonna-ankeetide järgi leibkondadesse (erilist tähelepanu vajavad juhtumid, kus üks inimene on loetud mitmesse leibkonda), selgitada iga leibkonna põhiline elukoht jne. Suure osa vastanute korral on ankeedid korralikult ja vastuoludeta täidetud ning kõik need protseduurid toimuvad automaatselt ja kiiresti, kuid suure vastanute arvu tõttu on loendusandmetes rohkesti ka selliseid segadusi, mis nõuavad andmetöötlejatelt mõttetööd ja ka muude allikate (nt rahvastikuregistri) kasutamist. Varasemate rahvaloenduste praktika näitab, et ankeetide töötlemisel lahendamist vajavate probleemide arv on suuruselt võrreldav täidetud ankeetide arvuga. See muidugi ei tähenda, et igas ankeedis oleks üks probleem. Vastupidi, leidub ankeete, milles on mitu probleemi ja nimelt nende lahendamine on eriti keerukas. Loendusandmestiku tegid keerukamaks ka mõned käesoleval aastal lisatud küsimused, mida varem pole rahvaloendustel Eestis küsitud. Üks uus küsimus oli kohaliku või murdekeele oskus, mille ümber oli küll üsna palju piikidemurdmist enne loendust, kuid millele kokkuvõttes siiski päris hästi vastati. Teine uus küsimus oli teine elukoht – kaugeltki kõigile ei olnud see mõiste selge. Kas suvila on teine elukoht? Millal on maakodu pere jaoks teine elukoht? Kas õppuri jaoks on teine elukoht vanematekodu või ühiselamu õpingute linnas?
Kõige probleemsem uus küsimus oli välismaale lahkunud lähisugulaste märkimine. Kuigi loendajad lootsid sellest küsimusest saada väga olulist infot väljarände kohta, tuleb enne lahendada terve hulk segadusi. Küll selgus, et sama inimene oli ühe sugulase poolt lahkunuks, teise poolt aga Eestis püsivalt elavaks märgitud, küll oli kummalisi vastuseid antud välismaale lahkumise aja suhtes (näiteks üle saja inimese olid märkinud sugulase lahkumise ajaks 2012, panemata tähele, et loendushetkel elas ju see inimene Eestimaal). Lahkumisajaks oli märgitud ka üsnagi kaugesse ajalukku ulatuvaid daatumeid.
Loendamata jäänud inimesed
Kõige ebameeldivam, kuigi mitte üllatav tõsiasi selgus loenduse lõppedes: osutus, et kõigist pingutustest ja väga edukast internetiloendusest hoolimata jäi mingi hulk Eesti püsielanikke loendamata. Vahetult pärast loenduse lõppu laekus statistikaametisse ridamisi teateid inimestest, kes olid loendamata jäänud. Loendamata jäämise põhjuseid oli mitmesuguseid: kas oli inimene loendusperioodil pikalt kodunt ära olnud või mingil arusaamatul põhjusel loendaja silmapaari vahele jäänud. Oli ka neid, kes ise tunnistasid, et ust lukus hoidsid ja postkasti ei vaadanudki. Kõige tüüpilisem põhjus seostus aga e-loendusega – leidus inimesi, kes märkisid loenduslehele aadressi, kus nad tegelikult ei elanud (kõige sagedamini aadressi, kuhu nad olid ametlikult registreeritud). Kui ankeet oli korrektselt täidetud, siis loendajad seda aadressi ei külastanud ja seal elavad inimesed jäid loendamata (kui nad ennast internetis ei loendanud).
Niisuguseid inimesi, kes loendamata jäid, on olnud kõigil loendustel, kuid nende arv on inimeste suurema liikuvuse tagajärjel praegusel ajal märksa suurem kui varasematel aegadel.
Loenduse kvaliteedi hindamisel on väga oluline mõiste kaetus, mis näitab, kui suur osa inimestest, kes loendamisele kuulusid, ka tegelikult loendati. Kui inimesi loendati vähem kui tarvis, on tegemist alakaetusega. Kui loendustulemus näitab tegelikust loendatavate arvust suuremat numbrit, on tegemist ülekaetusega. Ülekaetuse põhjuseks võib olla niihästi mõne isiku korduv loendamine kui ka loendamisele mittekuuluvate isikute arvamine loendatavate hulka. Rahvusvaheliselt on oletatud, et 2011. aasta loendusel on alakaetus keskmiselt vähemalt 1%, kuid riigiti üsnagi erinev.
Mida teha loendamata jäänud inimestega?
Loendajatel on alakaetuse korral kolm võimalikku valikut:
* Alakaetust eirata ja lugeda loendustulemus tegelikuks rahvaarvuks – nii on tehtud enamikus maades enamiku loenduste korral kuni tänapäevani.
* Kontrollida kaetust ja hinnata alakaetust, kuid siiski lugeda loendustulemus tegelikuks rahvaarvuks – nii tehti Eestis 2000. aastal ja nii on tehtud viimaste loendusvoorude puhul teisteski riikides.
*Kontrollida kaetust ja parandada loendustulemust, lugedes tegelikuks rahvaarvuks lisaks loendatutele ka loendamata jäänud isikud. See samm on rahvusvaheliselt aktsepteeritav, kuid seda on seni vähe rakendatud, sest puudub rahvusvaheliselt välja töötatud metoodika.
Esimene valik on olnud paratamatu varasematel ajalooperioodidel ja see pole ka suuri probleeme põhjustanud, sest lisaks sellele, et mõni inimene jäi loendamata, juhtus ka seda, et mõnda loendati korduvalt ja nii alakaetus ning ülekaetus kompenseerisid teineteist vastastikku. Käesoleval ajal aga on põhiprobleemiks alakaetus. Ülekaetust esineb loendustulemustes harvem, sest korduvalt loendatud isikud kõrvaldatakse loendatute hulgast, kasutades isikuid identifitseerivaid tunnuseid (isikukoodi).
Kaetuse kontrollimine ja loendustulemuste täiendamine on võimalik siis, kui on olemas alternatiivne infoallikas. Üks võimalus selleks on järelloendus. See võimaldab küll anda kaetusele hinnangu, kuid selle põhjal kaetust parandada pole hästi võimalik. Kaetuse parandamine, s.t mitteloendatud isikute lisamine arvestusliku rahvaarvu hulka on teostatav siis, kui riigis on piisavalt hästi toimiv registrite süsteem, millesse kuuluvad registrid on omavahel kooskõlas (lingitavad) ja nende andmeid ajakohastatakse ja täpsustatakse küllalt operatiivselt.
Viimaste aastate jooksul on Eesti registritesüsteemi põhjalikult analüüsitud ja pidevalt täiustatud. Sellesse kuuluvaid registreid kasutati oluliselt ka rahvaloenduse ettevalmistamisel (töönimekirjade koostamisel), läbiviimisel (eeltäidetud küsimused) ja andmetöötlusel (puudulike andmete täiendamine). Kuid registrite praegune tase võimaldab rohkematki – nende abil on võimalik loendustulemusi täpsustada ning leida Eesti praegusele rahvaarvule maksimaalselt täpne hinnang. See ei ole väga lihtne ülesanne, kuid matemaatilises statistikas on niisuguse ülesande lahendamiseks sobivaid meetodeid välja töötatud. Siinjuures tuleb arvestada, et nagu igasugune hinnang, sisaldab ka selline hinnang paratamatult viga.
Missuguseid vigu võib hindamisel esineda?
Üldises plaanis on viga alati halb asi, millest püütakse hoiduda. Viga tähendab, et tööd pole tehtud nii hästi kui võimalik, viga on tegijale etteheide.
Statistiku jaoks on veal hoopis teine tähendus. Juhuslik viga on statistikas kõigi otsustuste, kõigi hinnangute ja ennustuste paratamatu kaaslane. Ükskõik missugusest hinnangust, olgu majanduses või sotsiaalelus ka jutt pole, alati on see ligikaudne, mis tähendab, et see sisaldab juhuslikku viga. Enamasti selle vea suurust tavaväljaannetes ei märgita ja igapäevaelus pole sellel veahinnangul ka erilist tähtsust, kuid teadlaste jaoks on väga tähtis saada hinnangud, mis on võimalikult täpsed, s.t et juhuslik viga on võimalikult väike ja hinnang ei ole kuidagi kallutatud.
Edaspidi nimetame Eesti püsielanikke residentideks, ülejäänud inimesed – olgu nad kas pikemat aega välismaal elavad Eesti isikukoodiga inimesed või 2011. aastal Eestist vähemalt aastaks lahkunud – on mitteresidendid. Kasutades registrite andmeid Eesti rahvaarvu täpsustamiseks (sisuliselt REL2011 alakaetuse parandamiseks) on võimalik teha üks kahest põhimõtteliselt võimalikust veast: hinnata residentide arvu tegelikust suuremaks, s.t lugeda residentide hulka ka mitteresidente või hinnata residentide arvutegelikust väiksemaks, s.t jätta osa residente rahvaarvule lisamata.
Põhimõtteliselt on muidugi võimalik ka olukord, et otsustamisel ei tehtagi viga, kuid see on tavaliselt nii harv juhus, et seda ei võetagi arvesse. Nendel vigadel on elus tavaliselt erinev tähendus ja tähtsus. Uurijad nimetavad esimest liiki veaks tavaliselt selle, mida peetakse halvemaks, mida püütakse võimalikult vältida. Klassikaline näide on siin silla tugevuse mõõtmine – viga, mis tehakse, järeldades, et sild on piisavalt tugev, aga ta ei ole seda, on märksa halvem kui viga, mis tehakse, järeldades, et silda tuleb tugevdada, kuigi tegelikult seda vaja polekski.
Statistikameetodid võimaldavad hinnata otsustusprotsessis tehtavate vigade tõenäosusi ja otsustusmehhanism valida nii, et esimest liiki vea tõenäosus oleks ette määratud piirides, s.t küllalt väike. Paratamatult suureneb sellisel juhul teist liiki vea tõenäosus. Siiski on võimalik ka niisugune otsustusmehhanism, mille puhul mõlema vea tõenäosus on võrdne ja võimalikult väike.
Käesoleva ülesande lahendamisel on võimalik rakendada mitut erinevat strateegiat:
* Valida otsustusmetoodika selliselt, et esimest liiki vea tõenäosus oleks küllalt väike.
* Valida otsustusmetoodika selliselt, et esimest ja teist liiki vead oleksid omavahel võrdsed. Sel juhul saadaks rahvaarvule kõige täpsem hinnang.
Olles rahvaarvu täiendamisel ettevaatlikud ja konservatiivsed, nimetame esimesena kirjeldatud vea esimest liiki veaks ja piirame selle esinemise tõenäosuse näiteks arvuga 0,05. Teisena kirjeldatud viga on siis teist liiki. See tähendab, et iga saja mitteloendatud isiku lisamisel residentide hulka arvatakse juhusliku vea tõttu ekslikult residendiks ümmarguselt viis inimest. Tavaliselt käib sellega kaasas aga mõnevõrra suurema tõenäosusega esinev teist liiki viga, näiteks loetakse sajast tegelikust residendist kümme mitteresidendiks. Sellise meetodi rakendamisel saadakse rahvaarvule jätkuvalt mõnevõrra alakaetud hinnang.
Otsustamisel kasutatavad registrid
Eestis püsivalt elavad inimesed kuuluvad mitmesugustesse registritesse: peale rahvastikuregistri veel Haigekassa registrisse, sotsiaalkindlustuse registrisse, maksukohuslaste registrisse, hariduse infosüsteemi jne. Selgub, et keskmiselt jätab iga Eesti elanik aastas jälje kolme registrisse, kui aga arvestada registrite alamregistreid (nt Haigekassa registris on mitukümmend alamregistrit kindlustusliikide järgi), on see arv märksa suurem. Paljud registrid jäädvustavad inimeste tegevust aastas korduvalt – näiteks, kui inimene külastab korduvalt raviasutusi või saab eri kuudel tulu erinevatest allikatest. Seega on registrites olemas tõepoolest rikkalik andmestik otsustamaks, kas inimene elab Eestis ja tegutseb siin aktiivselt või teda ei ole siin. Kuid ometi ei ole see andmestik täiuslik.
Ühelt poolt on olemas inimesi, kes küll elavad Eestis ja keda siin ka loendati, kuid kes 2011. aastal üheski registris oma tegevusega ei kajastunud. Need on inimesed, kes on väljas õppurieast ja pole veel jõudnud pensioniikka, kes (ametlikult) ei tööta ega õpi, kuid pole ka töötud ning ei saa ei riigilt ega omavalitsuselt mingit toetust. Kui niisugune inimene pole ka arsti külastanud, juhieksamit sooritanud ega ka sattunud seadusega pahuksisse, ei ole tema kohta registrites 2011. aastal ühtegi jälge. Niisuguseid inimesi on Eestis kõige rohkem tööealiste meeste seas.
Teiselt poolt on ka selliseid inimesi, kes on Eestist lahkunud, kuid kasutavad jätkuvalt mõningaid Eesti riigi pakutavaid hüvesid. Näiteks lapsed ja noorukid, kes ei ole oma lahkumist registreerinud, on jätkuvalt Haigekassa registris ja võivad raviteenust saada, samuti võidakse nende arvel perele maksta lapsetoetust. Ka mootorsõiduki registreerimine Eestis ei tähenda alati seda, et isik elab Eestis. Selliseid näiteid võiks tuua veelgi. Need faktid sunnivad statistikuid ettevaatusele registrite kasutamisel inimeste residentsuse määramisel.
Kellele otsustusreeglit rakendada?
Kes on need inimesed, keda ei ole loendatud ja kes siiski võiksid olla Eesti püsielanikud? Kust neid õnnestub leida, kust saab nende nimekirja? Selle nimekirja loomiseks on taas mitu võimalust. Esimene tingimus, millele isik peab vastama, on see, et tal on Eesti isikukood, mille alusel saab kontrollida isiku kuulumist erinevatesse registritesse. Olgu siinkohal märgitud, et REL-meeskonna liikmed, kes selle ülesande lahendamisega tegelevad, ei näe inimeste tegelikke isikukoode ja selletõttu ei saa isikuandmeid inimestega siduda, vaid kasutavad krüptitud (juhuslikul viisil teisendatud) isikukoode, mis sobivad küll andmete seostamiseks, kuid mitte andmete sidumiseks konkreetse isikuga.
Üks variant potentsiaalsete residentide loetelu loomiseks on – luua koondnimekiri kõigist Eesti isikukoodiga isikutest, kes on mõnesse Eesti registrisse kantud, kuid keda REL2011 käigus Eesti püsielanikuna ei loendatud.
Teine variant on kasutada vaid nende inimeste nimekirja, kes on rahvastikuregistri andmetel Eesti püsielanikud, kuid keda REL2011 käigus ei loendatud.
See, kas võtta aluseks esimene (ilmselt mahukam) või teine (kitsam) nimekiri, määrab mingil määral lisanduvate isikute arvu. Lähtudes juba varem deklareeritud konservatiivsuse ja ettevaatlikkuse printsiibist on õigem analüüsida ainult rahvastikuregistris Eesti elanikena registreeritud, kuid REL2011 käigus loendamata jäänud isikuid.
Kuigi mingi hulk tegelikult Eestis elavaid inimesi võib olla ka nende seas, keda rahvastikuregistrisse ei ole üldse kantud või kes esinevad seal muude riikide elanikena, pole oletatavasti nende arv kuigi suur, mistõttu potentsiaalsete residentide rühma kuuluvad ainult niisugused inimesed, kes olid loendushetkel (31.12.2011) rahvastikuregistris kirjas Eesti elanikena ja keda REL2011 käigus ei loendatud.
Otsustamise metoodika
Põhimõtteliselt on võimalik otsustamisele läheneda kahel viisil: kas kasutada n-ö pehmet, eksperdihinnangutele tuginevat või kõva, s.o matemaatilist statistikat kasutavat metoodikat.
Eksperdihinnang. Registreid põhjalikult analüüsinud eksperdid selgitavad, missugused registrite kombinatsioonid suurema tõenäosusega viitavad olukorrale, et inimene elab püsivalt Eestis ja vastavalt sellele koostavad registrite põhjal otsustuseeskirja (nn indeksi). Indeksi väärtus arvutatakse iga potentsiaalse residendi jaoks. Kõige lihtsam indeksi näide on nende registrite arv, milles isikul 2011. aastal mingi aktiivne tegevus oli märgitud. Tegelikkuses kasutatakse siiski komplitseeritumaid indeksi eeskirju. Eksperdid määravad ka indeksi lävendi, lähtudes selle juures mingist ratsionaalsest printsiibist. Kõik inimesed, kelle jaoks arvutatud indeksi väärtus on suurem kui lävend, loetakse residentideks, aga need, kelle puhul indeksi väärtus jääb lävendist madalamaks, arvatakse mitteresidentide hulka. Käesolevas ülesandes on lävend määratud nii, et ühtegi isikut ei loeta residendiks ainult ühte registrisse kuulumise põhjal. Eksperdihinnangu puuduseks on selle subjektiivsus, ka pole eksperdihinnangutele alati võimalik arvutada usaldusväärseid veahinnanguid ja veatõenäosusi.
Diskriminantanalüüs on matemaatilise statistika meetod, mis on loodud objektide jaotamiseks etteantud rühmadesse. Meetodit saab rakendada olukorras, kus osa objekte on juba rühmitatud – need moodustavad nn õpperühmad, mille järgi koostatakse otsustuseeskiri. Osa objekte aga vajab veel rühmitamist ja nende puhul seda eeskirja rakendatakse. Diskriminantanalüüs sobib täpselt püstitatud ülesande lahendamiseks – residentide ja mitteresidentide eristamiseks.
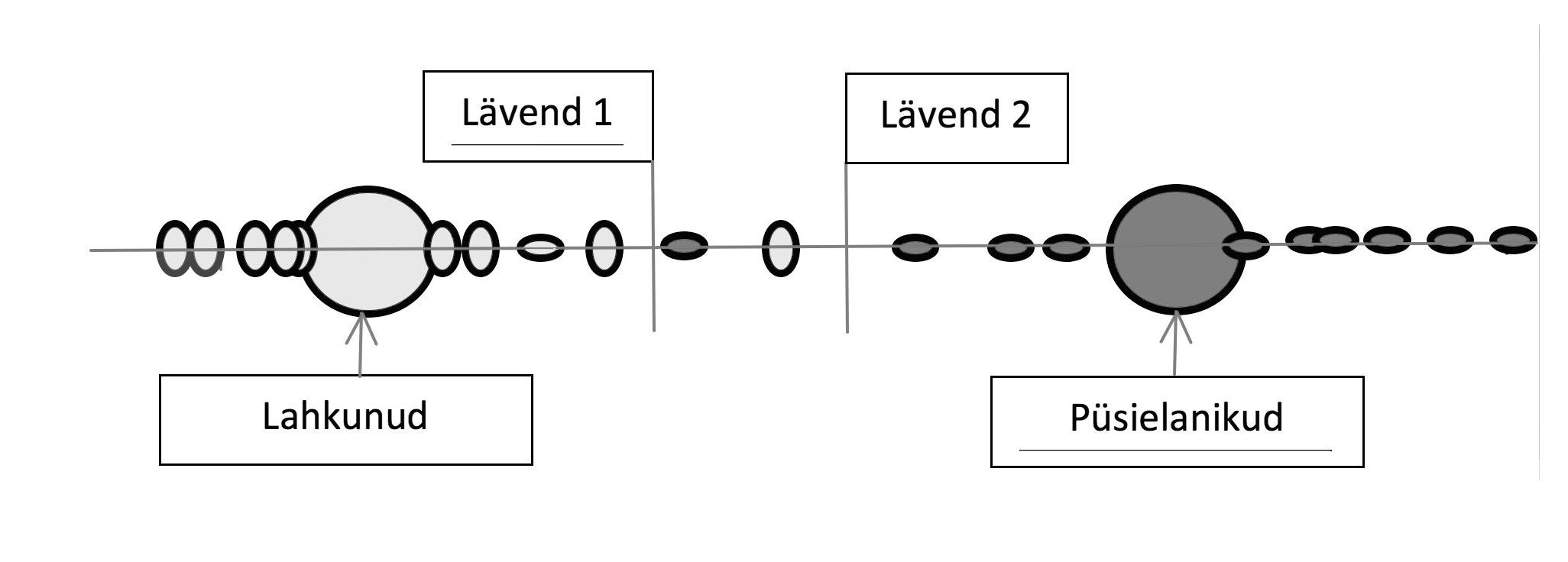
Õpperühmade moodustamiseks kasutatakse valikuliselt loendustulemusi. Kindlateks residentideks loetakse isikud, kes on end ise püsielanikena loendanud ja lisaks sellele on rahvastikuregistri andmetel Eesti elanikud. Mitteresidentideks loeti isikud, kes märgiti loendusel (lähedaste poolt) lahkunuks ja kes ei ela rahvastikuregistri andmetel Eestis. Kasutades kogu olemasolevat registriinfot moodustas vastav programm optimaalse eeskirja (diskriminantfunktsiooni), mis kaht õpperühma kõige paremini eristab. Vt lisatud joonist.
Sarnase diskriminantfunktsiooni väärtused arvutatakse (samuti nagu ka indeksi väärtused) iga potentsiaalse residendi jaoks ja residentideks loetakse need, kelle puhul diskrimineeriva funktsiooni väärtus ületab lävendi. Oluline erinevus võrreldes eksperdihinnangutega seisneb aga selles, et diskriminantanalüüsi puhul saab juba enne otsustamist arvutada otsustamisel tekkivad esimest ja teist liiki vea tõenäosused. Nende arvutatud veatõenäosuste põhjal määrab programm lävendi nii, et esimest liiki vea tõenäosus jääks lubatud piiridesse. Jooniselt on näha, et lävendi 1 puhul on võimalik nii esimest liiki viga (mõned mitteresidentidest, keda kujutavad püstised ellipsid, jäävad lävendist ülespoole, s.t määratakse residentideks), samuti on võimalik teist liiki viga – residendid (lamedad ellipsid) jäävad allapoole lävendit. Residentide keskpunkti suunas nihutatud lävend 2 aga muudab esimest liiki vea tõenäosuse väiksemaks (joonisel pole ühtegi mitteresidenti, kes oleks residendiks määratud), kuid seevastu teist liiki vea (resident määratakse mitteresidendiks) tõenäosus on suurem.
Diskriminantanalüüsi erinevus võrreldes eksperdihinnanguga seisneb selles, et diskriminantfunktsioon kasutab registrites sisalduvat infot optimaalselt ega sõltu ekspertide subjektiivsest teadmisest. Teine selle meetodi eelis on vigade arvutamise võimalus ja lävendi valimine vastavalt soovitavale vea tõenäosuse piirangule. On veel teisigi matemaatilisi meetodeid, mis sobivad püstitatud ülesande lahendamiseks, näiteks tänapäeval sageli kasutatav logistiline analüüs, mis hindab objektide teatavatesse rühmadesse kuulumise tõenäosusi.
Otsustusmetoodika valik ja tulemuste kontrollimine
REL-meeskond kasutab otsuse tegemisel mitut metoodikat, kusjuures residentide hulka arvatakse need isikud, kelle puhul erinevad meetodid annavad ühtelangeva tulemuse. Jälgitakse, et esimest liiki viga oleks mõistlikult piiratud, s.t et rahvastiku arvukust kindlasti ei ülehinnata.
Registreid kasutades saab langetatud otsustuste õigsust kontrollida. Selleks võrreldakse loendatud püsielanike ja otsustusreegli alusel määratud residentide aktiivsust registrites 2012. aasta alguses. Kui selgub, et need aktiivsuse näitajad on omavahel lähedased, siis pole alust arvata, et püsielanike hulka oleks arvatud valed inimesed või neid oleks lisatud liiga palju.
Loe Sirpi!

konverents „Luule erinevates varjundites“
Eesti Teatri Agentuuri teemapäev „teater | tulevik“
ERSO „Romantika“ sarja kontsert „Elts ja Brahms“
Ajateatri „Kes tappis trükkal Lackneri?“
Pealelend. Helmi Marie Langsepp, Ruumikoreograafia peatoimetaja
In memoriam Triin Tulgiste-Toss
Esiküljel režissöör Sander Maran. Foto Piia Ruber
Värsked artiklid
Leia veel huvitavat lugemist













